
tak's data blog
Model training(모델 훈련) 본문
머신러닝 리뷰의 모든 내용은 핸즈온 머신러닝을 기반으로합니다!!
지난 시간 분류(classification)에 이어서 오늘은 model training에 대해서 살펴보도록 하겠습니다.
가장 간단한 모델 중 하나인 linear regression부터 시작하겠습니다. 이 모델을 훈련시키는데는 두가지 방법이 있습니다.
1. 직접 계산가능한 공식을 사용하여 훈련 세트에 가장 잘 맞는 모델 파라미터를 구한다.
2. 경사 하강법(GD)라 불리는 반복적인 최적화 방식을 사용하여 파라미터를 조금씩 바꾸면서 비용함수를 최소화시킨다.
기본 개념

-> 가중치의 합과 bias로 이루어진 선형 모델(최적의 파라미터를 찾아 모델에 적합시켜 예측값을 구하자)
정규 방정식
- training set에 가장 잘맞는(비용함수를 최소화) parameter 도출
미분식 = 0을 만드는 값을 파라미터로 활용
정규 방정식 수식으로 입력하여 구하기
사이킷런 활용
-위와 동일한 결과출력
유사 역행렬
- 행렬 X_transpose * X 의 역행렬이 존재하지 않은 경우(어떤 특성이 중복되는 경우) -> 정규방정식 활용이 불가능
- 특잇값 분해singular value decomposition(SVD)라 부르는 표준 행렬 분해 기법을 사용해 계산.
훈련 세트 X를 다음과 같은 3가지의 행렬로 분해
유사 역행렬 : X+ = V * sigma+ * U^T
- 정규방정식과 달리 항상 사용 가능
계산 복잡도
-
정규방정식 : 계산복잡도가 n^2.4 ~ n^3 사이(특성 수가 두배로 늘어나면 계산시간이 대략 2^2.4=5.3에서 2^3=8배로 증가)
- 사이킷런의 LinearRegression 클래스가 사용하는 SVD 방법은 약 O(n^2)이다.
- 정규방정식, SVD 모두 특성 수가 많아지면 매우 느려진다. 샘플 수에 대해서 선형적으로 증가.
- 이 경우 사용하는 방법이 경사 하강법
경사 하강법 (gradient descent)
- 경사 하강법의 기본 아이디어는 비용 함수를 최소화하기 위해 반복해서 파라미터를 조정하는 것이다.
한번에 조금씩 비용함수가 감소되는 방향으로 진행하여 최솟값에 수렴할 때까지 점진적으로 향상
(학습 스텝 크기는 비용 함수의 기울기에 비례, 따라서 파라미터가 최솟값에 가까울수록 스탭 크기가 점진적으로 줄어든다.)
가장 중요한 파라미터는 스텝의 크기로, 학습률(learning rate)하이퍼 파라미터로 결정된다. 학습률이 너무 작으면 알고리즘이 반복을 많이 하므로 시간이 오래 걸린다.
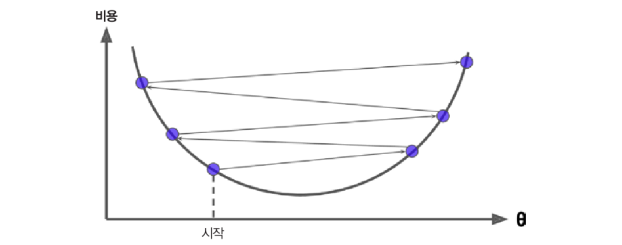
학습률이 너무 작을 때 : 반복을 많이 하므로 시간이 오래걸림
학습률이 너무 클 때 : 알고리즘을 더 큰 값으로 발산하게 만들어 정확도 하락
문제점
위와 같은 형태의 비용 함수는
1. 왼쪽에서 시작할 경우 : 전역 최솟값보다 덜 좋은 지역에 수렴
2. 오른쪽에서 시작할 경우 : 시간이 오래걸리고 평지에서 조기 종료될 수 있다.
해결 방안
- 경사 하강법을 사용할 때는 반드시 모든 특성이 같은 스케일을 갖도록 만든다. 그렇지 않으면 오래걸림.
- 사이킷런의 StandardScaler, MinMaxScaler, RobustScaler 등을 사용한다.
- 최솟값으로 수렴하는데 걸리는 시간 단축
배치 경사 하강법
- 전체 데이터 셋에 대한 에러를 구한 뒤, 기울기를 한 번만 계산하여 모델의 파라미터를 업데이트하는 법
-> 전체 학습 데이터를 하나의 배치로(배치 크기는 n) 묶어 학습
장점
- 전체 학습 데이터 셋에 대한 한번의 업데이트가 이루어져, 연산 횟수가 적다.
- 전제 데이터 셋에 대해 Gradient를 계산하여 진행, 최솟값으로의 수렴이 안정적.
단점
- 한 스텝에 모든 학습 데이터를 사용하므로 시간이 오래 걸린다.
- 지역 최적화(local optimal) 상태가 되면 빠져나오기 힘들다.
- 모델 파라미터의 업데이트가 이루어지기 전짜지 모든 학습 데이터 셋에 대해 저장해야 하므로, 많은 메모리 필요.
적절한 학습률(learning rate)을 찾으려면?
- Grid Search : 최적의 파라미터를 찾기 위한 과정 -> 반복 횟수 지정
- 어떻게 지정?
반복 횟수를 아주 크게 지정하고 gradient 벡터가 아주 작아지면, 경사 하강법이 최솟값에 도달한 것이므로 알고리즘을 중지하게끔 설정.
확률적 경사 하강법(SGD)
- 매 스텝에서 한 개의 샘플을 무작위로 선택, 그 하나의 샘플에 대한 gradient를 계산하는 법
장점
- 배치 경사 하강법보다 알고리즘이 빠르다.
- 메모리 차지 비중이 적다.
단점
- 비용 함수가 최솟값에 도달할 때까지 위아래로 요동치며 평균적으로 감소, 배치 경사 하강법보다 불안.
- 알고리즘이 멈출 때, 최적치가 아닐 수 있다.
확률적 경사 하강법의 무작위성은 지역 최솟값(local minimum)에서 탈출시켜줘서 좋지만, 알고리즘을 전역 최솟값(global minimum)에 다다르지 못하게 한다는 점에서 좋지 않다.
-> 학습률을 점진적으로 감소시키는 것 : 시작할 때는 학습률을 크게하고(지역 최솟값에 빠지지 않게), 점차 작게 줄여서 전역 최솟값에 도달하도록 한다.
미니 배치 경사 하강법
- 미니배치라 부르는 임의의 작은 샘플 세트에 대해 gradient를 계산하는 법(전체 데이터를 batch_size개씩 나눠 학습)
- 확률적 경사 하강법과 배치 경사 하강법의 절충안
장점
- 행렬 연산에 최적화된 하드웨어, GPU를 사용해서 향상된 성능
- 미니배치를 어느 정도 크게 하면, 알고리즘은 파라미터 공간에서 SGD보다 덜 불규칙하게 움직임.
- 즉, 미니배치 경사 하강법이 SGD보다 최솟값에 더 가까이 도달하게 될 것이다.
단점
- SGD보다 지역 최솟값(local minimum)에서 빠져나오기는 더 힘들 것이다.
다항 회귀(polynomial regression)
: 비선형 모델을 학습 시키는 기법
- 각 특성의 거듭제곱을 새로운 특성으로 추가, 추가된 특성을 포함한 데이터 셋에 선형 모델을 훈련
- 특성이 여러 개일 때 다항 회귀 모델을 사용하며느 특성 사이의 관계를 찾을 수 있다.
- PolynomialFeatures가 degree 옵션을 사용하여, 주어진 차수까지 특성 간의 모든 교차항을 추가하기 때문
- 단, 특성 수가 교차항을 포함해 엄청나게 늘어날 수 있으니 주의해야한다.
규제가 있는 선형 모델
- 과대적합을 막는 방법 중 하나는 모델을 규제하는 것(조건을 추가)
- 선형 회귀 모델에서는 모델의 가중치를 제한.
1. Ridge
비용 함수에 제곱항이 추가됨. (제곱항을 l2규제라고 함)
alpha = hyperparameter
- alpha = 0 이면, Ridge 회귀는 선형 회귀와 동일
- alpha가 매우 크면, 모든 가중치가 거의 0에 가까워지고 결국 데이터의 평균을 지나는 수평선이 된다.
alpha 증가시킬 수록 수평선이 된다.
- Ridge 회귀는 입력 특성의 스케일에 민감: 데이터의 스케일을 맞춰주는 작업이 중요하다.
- 규제가 있는 모델들에 대해서 일반적으로 진행해주는 작업
2. Lasso
비용 함수에 절댓값항이 추가됨. (절댓값항은 l1 규제라고 한다.)
-덜 중요한 특성(feature)의 가중치를 제거하려고 함.
-> 자동으로 특성을 선택하고 희소 모델(sparse model)을 만들어 줌 -> feature selection에 활용
3. Elastic Net
Ridge 회귀와 Lasso 회귀를 절충한 모델: L2 규제와 L1 규제를 결합
- 위 비용 함수 식에서 r = 0 이면 Ridge 회귀와 동일하고, r = 1이면 Lasso 회귀와 동일
- l1과 l2의 혼합 정도는 혼합 비율 r을 사용해서 조절한다.
각 모델은 언제 사용할까?
- Ridge가 기본적으로 많이 사용되지만, 특성이 몇개뿐이라고 의심되면 Lasso나 Elastic Net을 사용한다.
- 위 규제 모델들은 불필요한 특성의 가중치를 0으로 만들어준다.
-> 따라서 특성 수가 훈련 샘플 수보다 많거나 특성 몇개가 강하게 연관되어 있을 때 (다중 공선성이 존재할 때)는 보통 Lasso가 문제를 일으키므로 Lasso보다는 Elastic Net을 선호한다.
(Lasso는 불필요한 특성은 버리기 때문)
조기종료
- 검증 에러가 최솟값에 도달하면 바로 훈련을 중지 (조기 종료 되도록 규제를 거는 것)
- 확률적 경사 하강법이나 미니배치 경사 하강법에서는 곡선이 위와 같이 매끄럽지 않아서, 최솟값에 도달했는지 확인하기가 어렵다.
- 이에 대한 해결책은 검증 에러가 일정 시간동안 최솟값보다 클 때 (모델이 더 나아지지 않는다고 확신이 들 때) 학습을 멈추고, 검증 에러가 최소였을 때의 모델 파라미터로 되돌리는 것이 있겠다.
Logistic regression
- Target 변수가 범주형인 경우 사용하는 모델
- 샘플이 특정 클래스에 속할 확률을 추정하는데 사용 : 이진 분류 모델
- 각 클래스에 속할 확률을 비교해서, 확률 값이 큰 쪽으로 분류한다.
- 일반적으로 분류 기준 확률 값으로 0.5를 사용한다.
- 시그모이드 함수 사용
- y = 1에 대해서는 높은 확률을 추정하고, y = 0에 대해서는 낮은 확률을 추정하는 모델의 파라미터 벡터의 theta를 찾는 것
- 비용 함수
모든 훈련 샘플의 비용 함수를 평균 낸 것 -> 볼록 함수
-> 경사 하강법 같은 알고리즘으로 최솟값 찾기
양쪽의 확률이 0.5가 되는 1.6즈음에서 결정 경계 생성
1.6이상이면 Iris-Virginica로 분류
- l1, l2 규제 적용 가능
Multiple logistice regression (softmax regression)
- (범주가 2개로 이루어진) Target 변수가 2개 이상인 경우
- 샘플 x가 주어지면 다항 로지스틱 회귀 모델이 각 클래스 k에 대한 점수를 계산하고, 그 점수에 정구화된 지수 함수(소프트 맥스 함수)를 적용하여 각 클래스의 확률을 추정하는 방식
- 추정 확률이 가장 높은 클래스를 선택 : 가장 높은 점수를 가진 클래스를 선택
'머신러닝' 카테고리의 다른 글
| 추천시스템(Recommendation system) 유사도(similarity) (0) | 2021.03.26 |
|---|---|
| 추천시스템(Recommendation system) (1) | 2021.03.26 |
| Decision Tree(의사결정나무) (0) | 2021.03.02 |
| classification(분류) (0) | 2021.02.02 |
| 머신러닝이란? (0) | 2021.01.26 |



