
tak's data blog
[BOAZ 프로젝트] 카카오맵 카페 크롤링 2(수정) 본문
프로젝트가 6월까지이므로 이제 슬슬 크롤링을 마무리할 단계가 다가왔습니다... 현재 진행상황으로는 user_id / 리뷰 / 평점 / 리뷰를 작성한 시간 / 카카오맵 url 이렇게 5개의 칼럼으로 데이터프레임의 형식을 맞추려고 하고 있습니다!
크롤링하면서 상당부분의 음식점이 없는 것으로 나와있고, 음식점이 아닌 병원이 나오는 경우도 있어서 추후에 보완할 필요가 있어보입니다. 총 13만개의 데이터를 작업해야 하는데 노트북을 하루종일 켜놔야 할 것 같네요 ㅠㅠ
저번에 작성한 코드가 아닌 data-page = "숫자" 안에 페이지별로 숫자가 달라지는 규칙을 가지고 새로운 코드를 작성하게 되었습니다.

카카오 크롤링 거의 마지막 코드
driver = webdriver.Chrome(r'C:/Users/user/Desktop/dd/Data_Handling/chromedriver.exe')
driver.maximize_window()
count = 0
current = 0
goal = len(items)
for item in items :
current += 1
print('진행상황 : ', current,'/',goal,sep="")
# 리뷰가 없을 때의 코드
driver.get("https://map.kakao.com/") # 카카오 지도 접속하기
searchbox = driver.find_element_by_xpath("//input[@id='search.keyword.query']") # 검색창에 입력하기
searchbox.send_keys(item)
time.sleep(2)
searchbutton = driver.find_element_by_xpath("//button[@id='search.keyword.submit']") # 검색버튼 누르기
driver.execute_script("arguments[0].click();", searchbutton)
time.sleep(2)
if len(driver.find_elements_by_xpath("//a[@class='moreview']")) != 0:
print('식당 존재')
driver.execute_script('window.open("about:blank", "_blank");') # 새 탭 열기
reviewbutton = driver.find_element_by_xpath("//a[@class='numberofscore']")
time.sleep(2)
content_url = reviewbutton.get_attribute("href")
tabs = driver.window_handles
driver.switch_to_window(tabs[1]) # 새 탭으로 이동
driver.get(content_url) # 링크 열기
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
review_lists = soup.select('.list_evaluation > li')
print(len(review_lists))
if len(review_lists) != 0 :
for i, review in enumerate(review_lists) :
user_review = review.select('.txt_comment > span') # 리뷰
rating = review.select('.grade_star > em') # 별점
try:
img_url = review_lists[i].select_one('a.link_photo > img ')['src']
except:
continue
user_id = review.select('.append_item > a[data-userid]') # user 정보 html 파싱
timestamp = review.select(' div > span.time_write') #시간정보
try:
row = {"UserID":user_id[0].get('data-userid'),"ItemID":item,"Rating":rating[0].text,"Timestamp":timestamp[0].text}
row = pd.DataFrame(row, index=[i])
rating_df = rating_df.append(row,ignore_index=True)
review_row = {"ItemID" : item, "review" : user_review[0].text}
review_row = pd.DataFrame(review_row, index=[i])
review_elem = review_elem.append(review_row, ignore_index = True)
try :
img_row = {"UserID":user_id[0].get('data-userid'),"ItemID" : item, "img_url" : img_url}
img_row = pd.DataFrame(img_row, index=[i])
img_elem = img_elem.append(img_row, ignore_index=True)
except :
img_row = {"UserID":None,"ItemID" : item, "img_url" : None}
img_row = pd.DataFrame(img_row, index=[i])
img_elem = img_elem.append(img_row, ignore_index=True)
time.sleep(3)
except:
row = {"UserID":None,"ItemID":item,"Rating":None,"Timestamp":timestamp[0].text}
row = pd.DataFrame(row, index=[i])
rating_df = rating_df.append(row,ignore_index=True)
review_row = {"ItemID" : item, "review" : user_review[0].text}
review_row = pd.DataFrame(review_row, index=[i])
review_elem = review_elem.append(review_row, ignore_index = True)
try :
img_row = {"UserID":user_id[0].get('data-userid'),"ItemID" : item, "img_url" : img_url}
img_row = pd.DataFrame(img_row, index=[i])
img_elem = img_elem.append(img_row, ignore_index=True)
except :
img_row = {"UserID":user_id[0].get('data-userid'),"ItemID" : item, "img_url" : None}
img_row = pd.DataFrame(img_row, index=[i])
img_elem = img_elem.append(img_row, ignore_index=True)
time.sleep(1)
else :
print("리뷰가 없습니다")
try:
for i in range(2,500):
time.sleep(3)
another_review = driver.find_element_by_xpath("//a[@data-page='" + str(i) + "']")
another_review.click()
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
review_lists = soup.select('.list_evaluation > li')
if len(review_lists) != 0 :
for i, review in enumerate(review_lists) :
user_review = review.select('.txt_comment > span') # 리뷰
rating = review.select('.grade_star > em') # 별점
try:
img_url = review_lists[i].select_one('a.link_photo > img ')['src']
except:
continue
user_id = review.select('.append_item > a[data-userid]') # user 정보 html 파싱
timestamp = review.select(' div > span.time_write') #시간정보
try:
row = {"UserID":user_id[0].get('data-userid'),"ItemID":item,"Rating":rating[0].text,"Timestamp":timestamp[0].text}
row = pd.DataFrame(row, index=[i])
rating_df = rating_df.append(row,ignore_index=True)
review_row = {"UserID":user_id[0].get('data-userid'), "ItemID" : item, "review" : user_review[0].text}
review_row = pd.DataFrame(review_row, index=[i])
review_elem = review_elem.append(review_row, ignore_index = True)
try:
img_row = {"UserID":user_id[0].get('data-userid'),"ItemID" : item, "img_url" : img_url}
img_row = pd.DataFrame(img_row, index=[i])
img_elem = img_elem.append(img_row, ignore_index=True)
except:
img_row = {"UserID":user_id[0].get('data-userid'),"ItemID" : item, "img_url" : None}
img_row = pd.DataFrame(img_row, index=[i])
img_elem = img_elem.append(img_row, ignore_index=True)
time.sleep(1)
except:
row = {"UserID":None,"ItemID":item,"Rating":None,"Timestamp":timestamp[0].text}
row = pd.DataFrame(row, index=[i])
rating_df = rating_df.append(row,ignore_index=True)
review_row = {"UserID":user_id[0].get('data-userid'),"ItemID" : item, "review" : user_review[0].text}
review_row = pd.DataFrame(review_row, index=[i])
review_elem = review_elem.append(review_row, ignore_index = True)
try :
img_row = {"UserID":user_id[0].get('data-userid'),"ItemID" : item, "img_url" : img_url}
img_row = pd.DataFrame(img_row, index=[i])
img_elem = img_elem.append(img_row, ignore_index=True)
except :
img_row = {"UserID":user_id[0].get('data-userid'),"ItemID" : item, "img_url" : None}
img_row = pd.DataFrame(img_row, index=[i])
img_elem = img_elem.append(img_row, ignore_index=True)
except:
print("더 이상 리뷰 존재 X")
driver.close()
driver.switch_to_window(tabs[0])
print("기본 페이지로 돌아가자")
else:
print("식당 존재 x")
확실히 전에 작성한 코드에 비해 많이 간결해진게 보입니다.
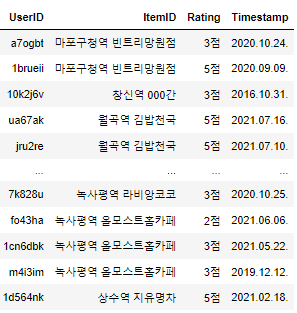
데이터 프레임 결과
현재 이러한 형식으로 데이터 프레임을 뽑고 있습니다. 상당히 진전이 된 것 같아서 다행이네요..
현재는 컨퍼런스와 함께 adv프로젝트를 끝마치고 최종적으로 수정된 데이터 프레임은 아래와 같습니다.

'BOAZ' 카테고리의 다른 글
| [BOAZ 프로젝트] json 파일 이미지 다운 (1) | 2021.07.13 |
|---|---|
| [BOAZ 프로젝트] 크롤링 데이터 프레임화 (1) | 2021.07.12 |
| [BOAZ 프로젝트] 카카오맵 카페 크롤링1 (0) | 2021.03.09 |
| [BOAZ 프로젝트] google maps api로 경도/위도 가져오기 (0) | 2021.02.22 |
| [BOAZ 프로젝트] 지하철역별 카페추천시스템 (0) | 2021.02.22 |
'BOAZ' Related Articles
more



