
tak's data blog
[kaggle] 필사하기 (Porto Seguro's Safe Driver Prediction) 본문
저번주 santander에 이어서 이번주는 포르토 세구로에서 주최한 안전 운전자 예측 경진대회에대해 다루어 보겠습니다.
우선 '머신러닝 탐구생활' baseline을 기반으로 필사한점을 인지해주시기 바라겠습니다!
캐글 커널 주소 : www.kaggle.com/c/porto-seguro-safe-driver-prediction
대회의 평가 척도로는 [정규화 지니 계수]를 사용합니다.
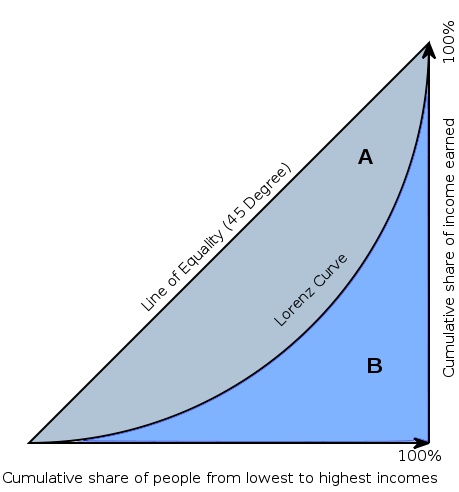
간단하게 설명드리자면 불균형의 정도를 나타내는 통계학적 지수로, 지표는 경제 분야에서 소득별 부의 불균형 정도를 나타내는데 사용합니다. 지니 계수는 회색 gini index의 면적을 삼각형 전체의 면적으로 나눈 값을 의미합니다. 부의 불균형이 높을 수록 gini index영역은 더 커지고, 그에 따라 지니 계수 또한 높아질 것입니다. 데이터에서의 지니계수는 1에 가까울수록 좋습니다.
대회 정보
- 운전자가 내년에 보험을 청구할 확률을 예측하는 대회.
- 정규화 지니계수 사용(0에 가까울수록, 예측 모델의 정확도가 낮다는 의미이며 1에 가까울수록 성능이 좋다.)
주요 아이디어
- Gradient Boosting Decision Tree 라이브러리의 대표인 LightGBM을 사용.
- 변수의 익명화
- '_bin'으로 끝나는 변수는 이진변수이고, '_cat'으로 끝나는 변수는 범주형 변수이다. '-1'값은 결측값이다.
- 결측값의 개수로 파생 변수 생성, 범주형 변수를 onehotencoding하여 새로운 변수 생성
1. 탐색적 데이터 분석

데이터의 구조를 살펴보면 훈련, 테스트 데이터가 각각 59만명, 89만명의 데이터를 포함하고 있다.
변수의 갯수가 1개가 차이나는 이유는 예측을 위한 테스트 데이터에는 운전자의 보험 청구 여부를 나타내는 'target' 변수를 포함하지 않기 때문일것이다.
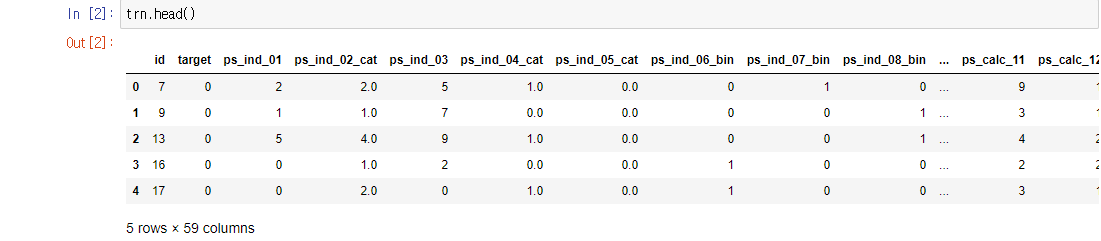
데이터를 조금 살펴보면 모든 변수가 'ps_ind'와 같은 형태로 익명화 되어있고, info결과 수치형 데이터인것을 확인할 수 있었습니다.
변수명을 통해서 뒤에 '_cat'으로 끝나면 범주형(categorical)변수이고 '_bin'이면 이진(binary)변수라는 점을 확인할 수 있었습니다.
1) 변수 시각화
데이터를 살펴보는 것만큼 또 중요한 것은 없죠
데이터 타입별로 4개의 그룹으로 나눈 후 시각화를 시작하겠습니다.
시각화를 위해서 훈련, 테스트 데이터를 통합하여 새로운 데이터(df)를 생성합니다.
대표적 몇개의 그래프만 살펴보겠습니다.
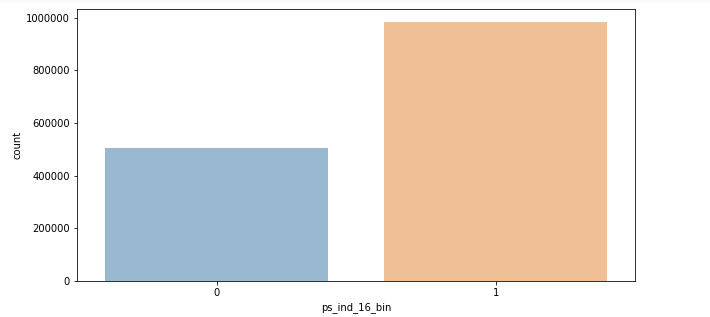
이진 변수 분포에서 각각 변수별 차이가 있다는 것을 확인할 수 있었습니다.
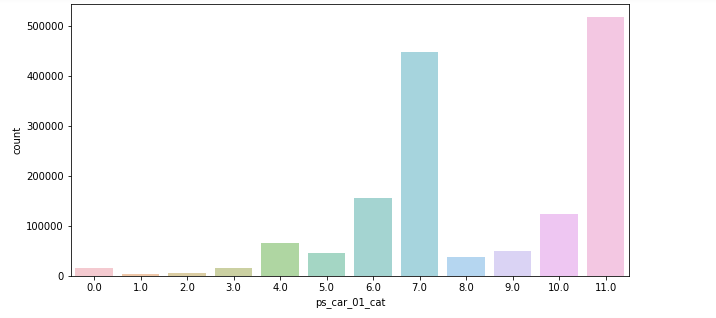
범주형 변수 분포로 고유값이 2개에서 최대 100개 이상까지 존재하는 변수를 확인할 수 있었고,
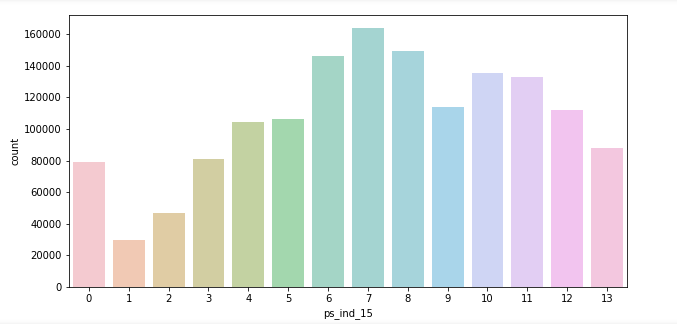
이처럼 정규분포형태를 띄는 그래프도 존재했습니다.
시각화를 토대로 직접 데이터 정리표를 작성해보았스비다. 참고해주시면 감사하겠습니다.
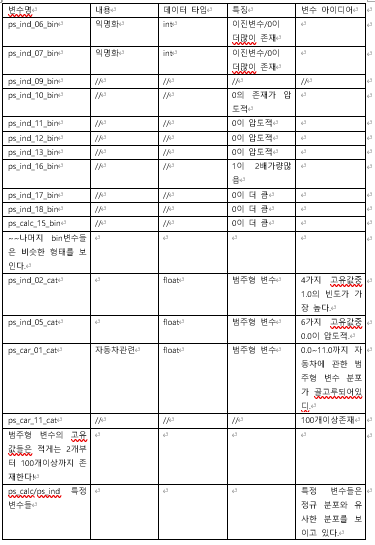
데이터 정리표를 작성하는 습관을 들이니 한눈에 보기 좋고 잊어먹거나 하는 실수가 줄어드는것 같아 추천합니다 ㅎㅎ
2) 상관관계 heatmap 그래프 시각화

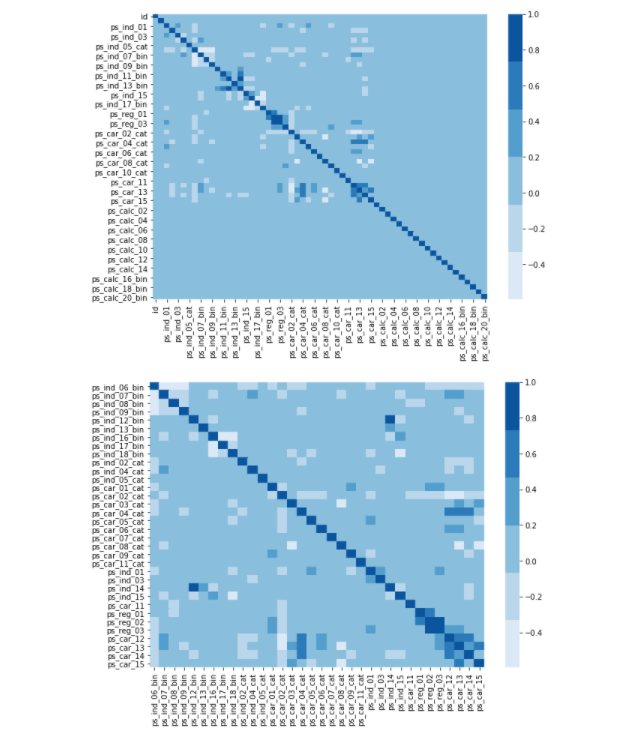
상관관계를 시각화 했지만 대부분의 변수들간의 상관관계가 낮았고, ps_ind_14와 ps_ind_12_bin 두 변수가 높은 상관관계를 가집니다.
다음 훈련 데이터와 테스트 데이터의 분포를 비교하는 과정이 아직 시각화나 EDA이 과정이 미흡한 저는 생각지도 못해서 흥미로웠습니다.
훈련 데이터와 테스트 데이터의 분포를 비교하는 시각화는 매우 중요하다. 심각하게 다르면 학습한 의미가 없어지기 때문이다.

테스트 데이터가 훈련데이터의 약 1.5배 분량이므로 이를 시각화 분포를 통해 알아보았습니다.
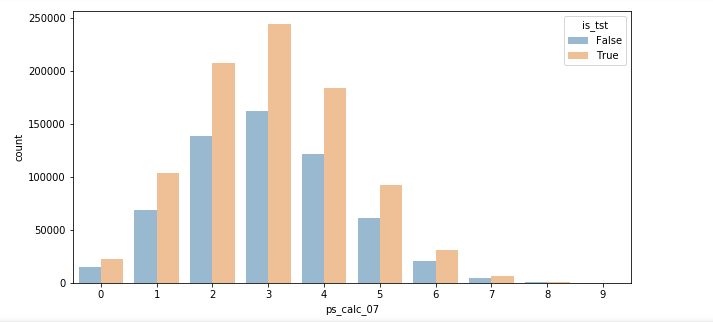
모든 변수에 대해서 위와 같이 파란색이 훈련데이터임에 따라 테스트 데이터가 1.5배 비율로 더 높고 비슷한 분포를 가진다는 것을 확인할수 있었습니다.
탐색적 데이터 분석 요약
- 제공된 데이터는 모두 정수형, 소수형이라 깔끔한 데이터 타입.
- 데이터를 총 4개['ind', 'calc', 'car', 'reg']의 그룹으로 변수를 군집.
- 그러나 익명화로 인한 변수를 정확히 이해+유의미한 파생 변수 생성 과정이 어렵다.
2. Baseline 모델
원래 대부분의 데이터는 전처리 과정을 통해 문자열 데이터나 '나이' 등이 정상적인 수치형 데이터로 표현하지 않을 경우 수정해야 하는데 이번 데이터는 전처리 과정이 불필요합니다.
1) 피처 엔지니어링
이번 모델에서는 3가지 기초적인 피처 엔지니어링을 수행합니다.
- 결측값의 개수를 나타내는 missing 변수
- 이진 변수들의 총합
- Target Encoding 파생 변수

우선 id와 target을 분리해줍니다.

3가지 파생 변수를 생성하기 위한 코드입니다.
- 파생변수 1 : 운전자별 결측값의 개수를 더함. -> 결측값이라도 데이터 특성상 초보운전자의 정보가 적을 수 있으므로 좋은 정보가 가능.
- 파생변수 2 : 이진 변수는 값의 특성상 변수가 파생 변수에 미치는 영향력이 균등.
- 파생변수 3 : 단일변수 타겟 비율 분석으로 선정한 변수를 기반으로 Target Encoding을 수행하는데 Target Encoding은 교차 검증 과정에서 진행한다.
ex) 'ps_ind_01' 변수 값이 0일 경우, 'ps_ind_01 변수 값이 0인 모든 운전자들의 평균 타겟 값을 'ps_ind_01_target_enc'파생 변수로 사용.
2) LightGBM 모델 정의
LightGBM의 모델의 파라미터 튜닝에 대한 공부를 다시해 정리해서 올려보도록 하겠습니다.

3) 모델 학습 및 교차 검증 평가
시계열 데이터 특성을 지니지 못했으므로 데이터를 랜덤하게 분리하여 교차 검증에 활용한다.
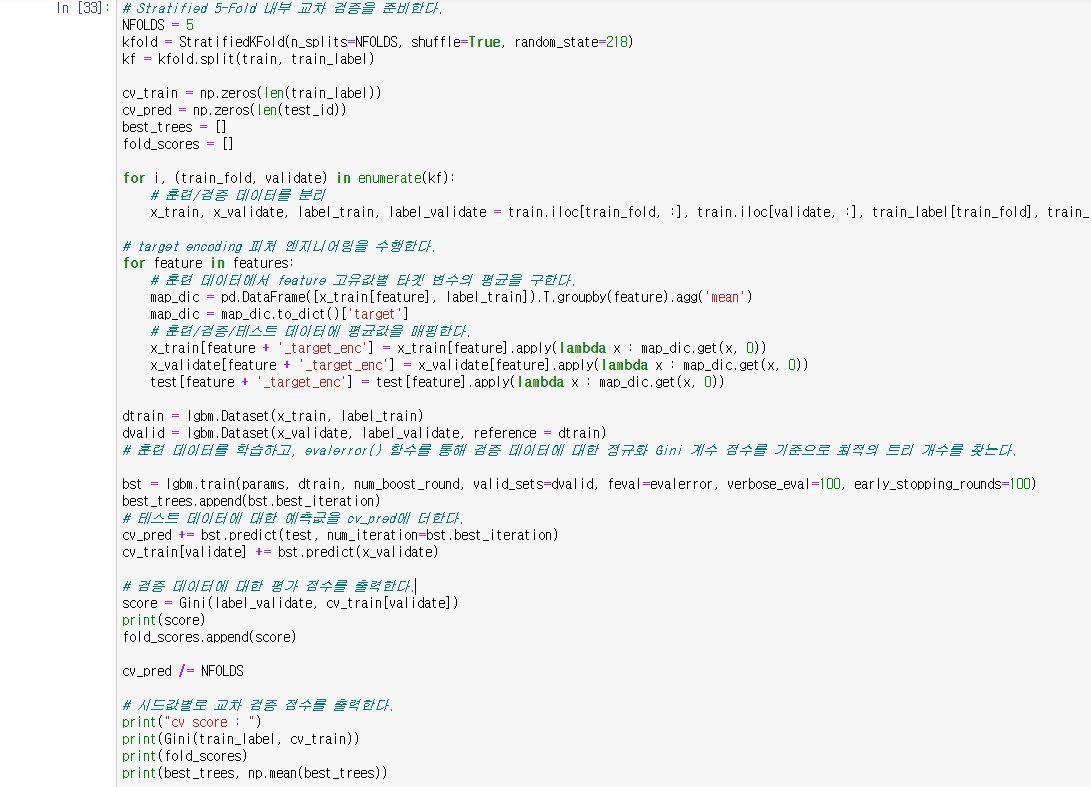
이렇게 모든 과정을 마치고 나면 Baseline 모델의 Public 점수는 0.28119점에 해당합니다. 점수를 높이기 위해서 피처 엔지니어링을 수정하거나 추가하는 방향으로 나아가야 할 것 같습니다.
Baseline 모델이므로 추후에 kaggle 1,2 등 커널을 다시 공부해서 분석하는 방향으로 포스트를 또 올려보겠습니다. 놓쳤던 부분이나 새로웠던 부분 위주로 정리해보겠습니다.
다음 포스팅에서 뵙겠습니다.
감사합니다!!
'Kaggle' 카테고리의 다른 글
| [kaggle] 데이터분석 진행해보기(중고차 가격 예측) (1) | 2021.03.08 |
|---|---|
| [kaggle] 필사하기 (Home Credit Default Risk) (0) | 2021.02.13 |
| [kaggle] 필사하기 (Santander Product Recommendation) (0) | 2021.01.21 |


