
tak's data blog
[kaggle] 데이터분석 진행해보기(중고차 가격 예측) 본문
전 게시글들은 kaggle 필사를 기준으로 진행하였습니다. 이번에는 직접 데이터를 살펴보고 분석해보는 과정으로 진행해보록 하겠습니다!!
참고 블로그 : ebbnflow.tistory.com/141?category=850456
[캐글] 중고차 가격 예측 모델2_Gradient Boost, Random Forest
● Gradient Boost Gradient Boosting Algorithm (GBM)은 회귀분석 또는 분류 분석을 수행할 수 있는 예측모형이며 예측모형의 앙상블 방법론 중 부스팅 계열에 속하는 알고리즘입니다. Gradient Boosting..
ebbnflow.tistory.com
데이터는 kaggle 중고차 가격 예측 대회를 참고하였습니다.
필요한 라이브러리들을 import하고
train데이터를 살펴봅니다.

간단하게 살펴보면 Name / Mileage / Engine / Power 등은 문자열 처리가 필요할 것으로 보입니다.
info로 데이터 타입을 살펴보고 object형태 중 문자열 처리를 통해 float형태로 바꿔 써야 할 것 같습니다.

데이터타입에따라 integer/ float/ categorical로 나누고 각 고유값들을 살펴보도록 하겠습니다.
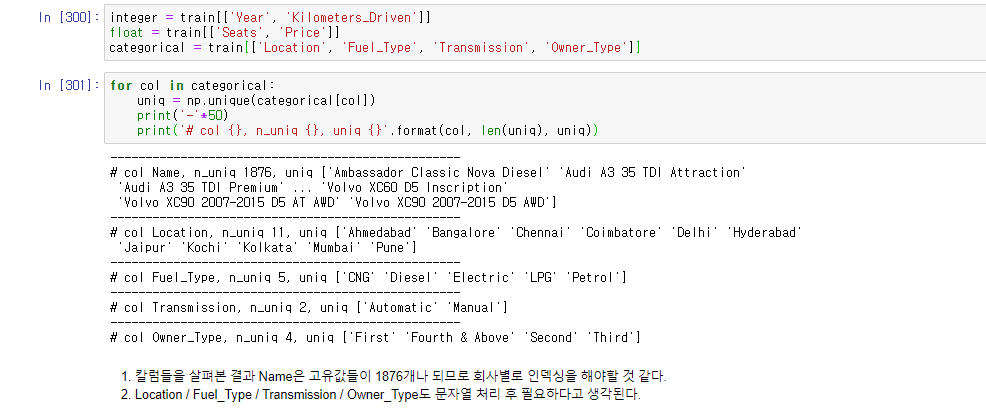
Name의 고유값은 1876개나 되는데 이는 차종이므로 후에 예를들어 현대차, 도요타 등등 회사별로 나누는 과정을 가지겠습니다.
plot을 통한 시각화로 분포를 살펴보겠습니다.
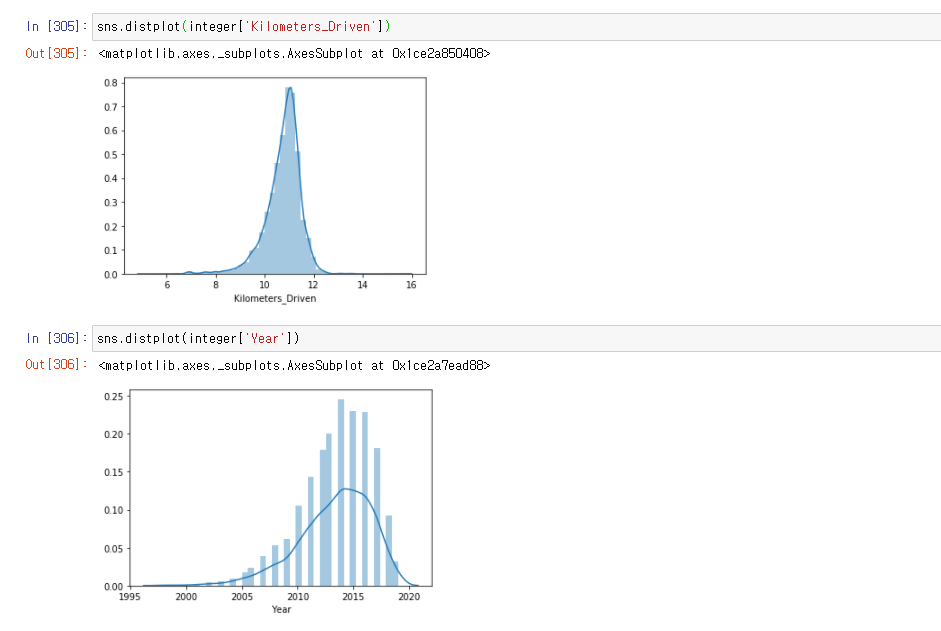
Kilometers_Driven은 너무 값이 치우쳐져 있어 log를 통해 살펴보았고, year는 2010~2018정도에 치우쳐진 것을 확인 할 수 있었습니다.

categorical 변수
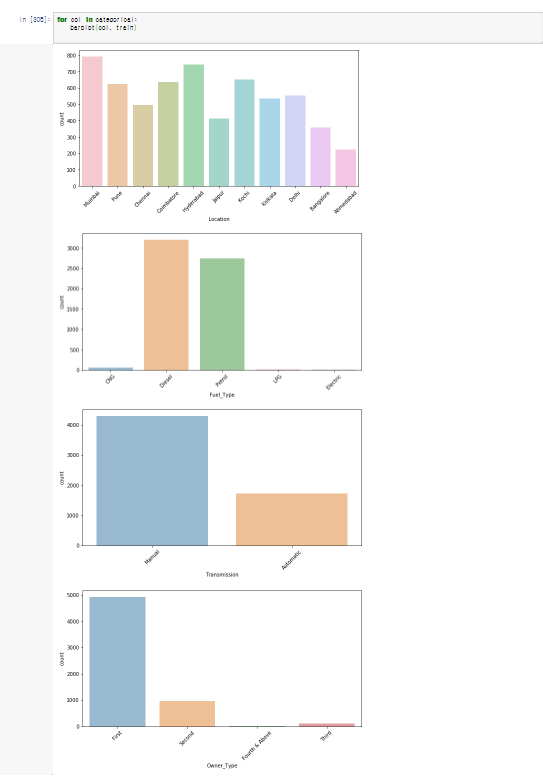
1. Bangalore / Ahmedabad/ Jaipur이 상대적으로 적다.
2. Mumbai / Hyderabad 가 상대적으로 크다.
3. Diesel / Petrol이 압도적으로 크다.
4. Manual이 Auto보다 상대적으로 2배정도 크고
5. Owner_type은 first와 second에 몰려있다.
결측값 확인

new_price의 지나치게 많은 결측값으로 필요없다고 판단되어 저 열만 삭제하고 진행하겠습니다.

name 정리

위에서 말씀드렸다시피 회사별로 정리하는 과정을 거치고
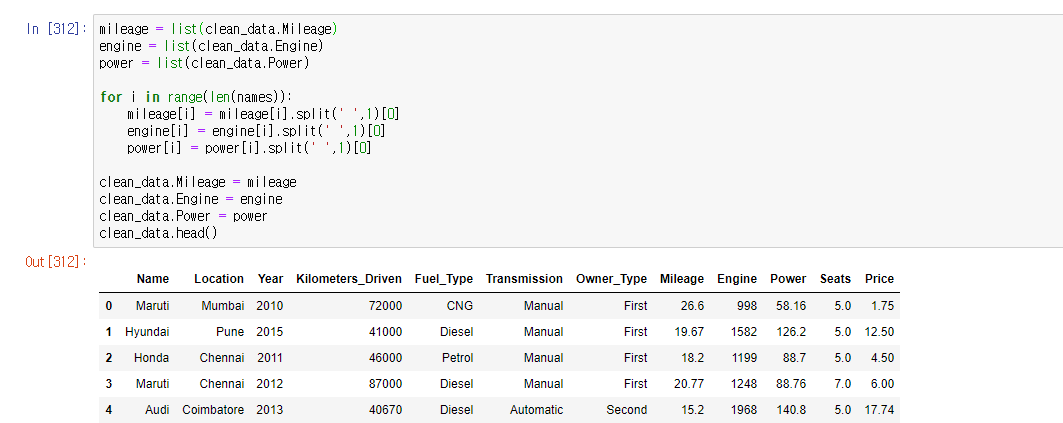
mileage / engine / power 변수의 문자열을 제거 후 float형으로 바꾸는 과정을 거칩니다.

Heatmap

one-hot encoding
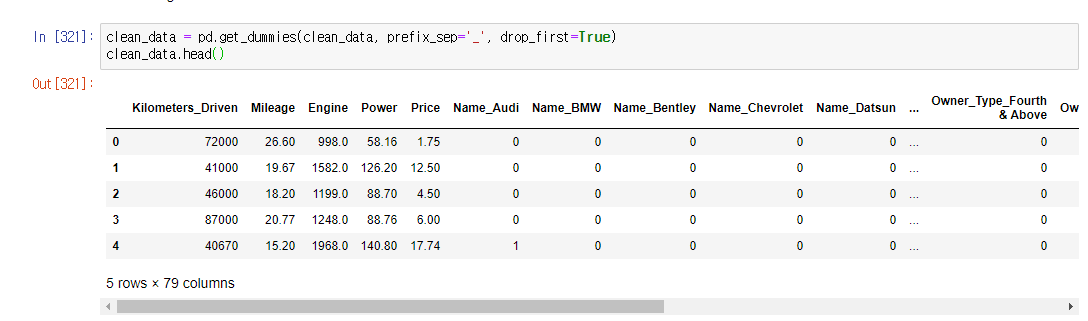
학습을 위한 원핫인코딩 후
boxplot
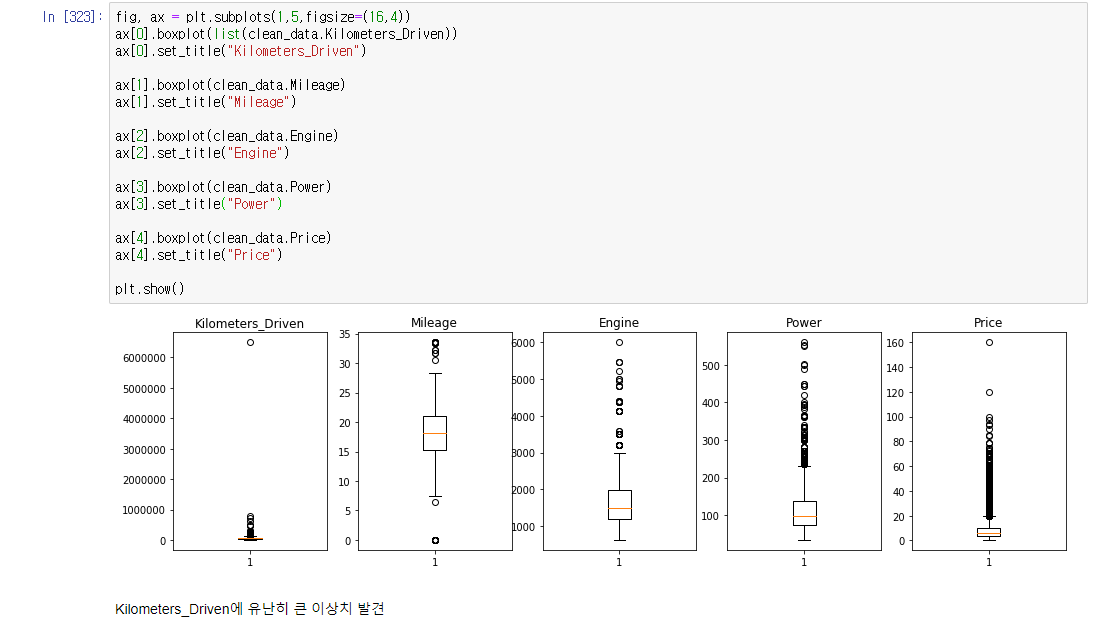
이상치 확인을 위한 boxplot
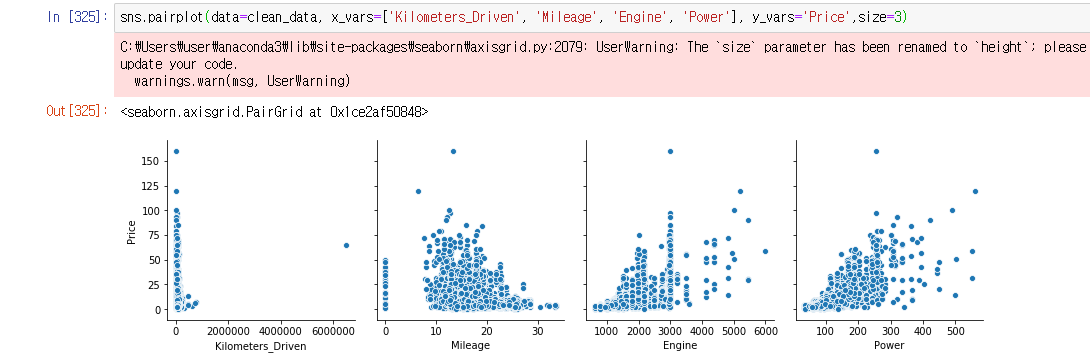
pairplot
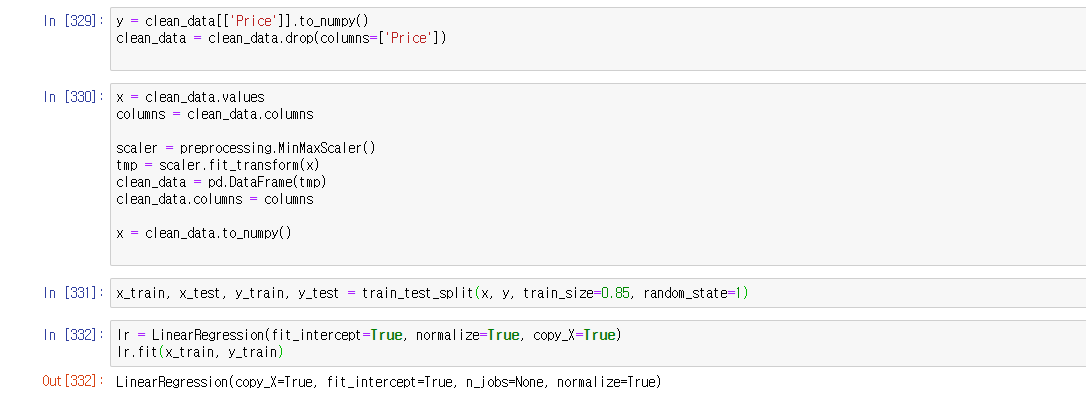
scale과정을 거친 후 트레인/테스트 셋 분리
로지스틱 회귀 결과
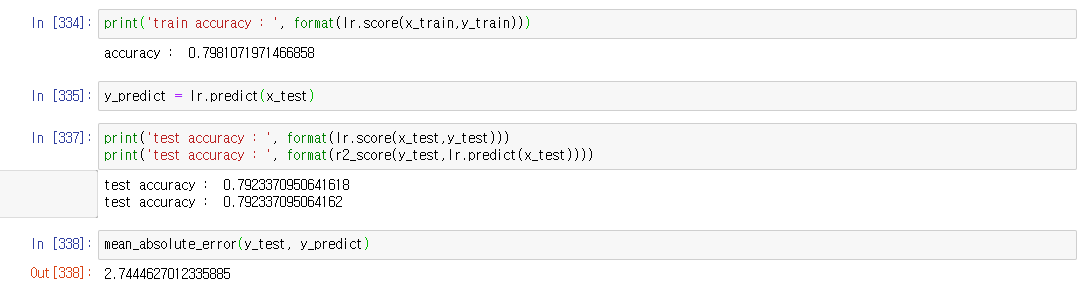
정확도가 그리 높진 않지만 그래도 테스트와 트레인 셋의 차이가 크지 않고 준수하다고 보여집니다.
GradientBoostingRegresoor 결과
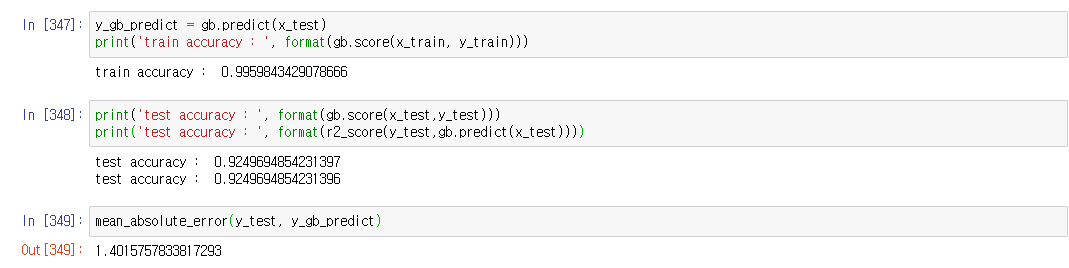
로지스틱 회귀보다 확실히 높은 정확도를 얻게 되었고 mae값도 줄어든 것을 확인 할 수 있었습니다.
Randomforestregressor 결과

로지스틱보다는 좋은 결과를 가지지만 gradientboosting에 비해서는 낮은 정확도를 보입니다.
칼럼수가 많은 모델은 다중선형회귀보다는 앙상블 모델을 이용해야 잘 돌아가는 것을 확인할 수 있었습니다.
이상 캐글 자동차 예측 경진대회 리뷰였습니다 감사합니다 :)
'Kaggle' 카테고리의 다른 글
| [kaggle] 필사하기 (Home Credit Default Risk) (0) | 2021.02.13 |
|---|---|
| [kaggle] 필사하기 (Porto Seguro's Safe Driver Prediction) (0) | 2021.01.26 |
| [kaggle] 필사하기 (Santander Product Recommendation) (0) | 2021.01.21 |


