
tak's data blog
[kaggle] 필사하기 (Home Credit Default Risk) 본문
www.kaggle.com/c/home-credit-default-risk
Home Credit Default Risk
Can you predict how capable each applicant is of repaying a loan?
www.kaggle.com
이번에 다룰 필사할 kaggle competition은 Home Credit Default Risk로 과거 대출 신청 데이터를 사용하여 신청자가 대출금을 상환할 수 있는지 여부를 예측하는 대회입니다.
참고 커널 : www.kaggle.com/willkoehrsen/start-here-a-gentle-introduction
Start Here: A Gentle Introduction
Explore and run machine learning code with Kaggle Notebooks | Using data from Home Credit Default Risk
www.kaggle.com
대회 정보
- 대출금의 상환 여부를 예측하는 대회.
주요 데이터 : application_train/application_test 홈 크레딧의 각 대출 애플리케이션에 대한 정보가 포함된 기본 교육 및 테스트 데이터입니다. 모든 대출에는 자체 행이 있으며 기능 SK_ID_CURR로 식별 됩니다. training data의 target 데이터는 0 : 대출금이 상환되었거나, 1: 대출금이 상환되지 않았음을 나타낸다.

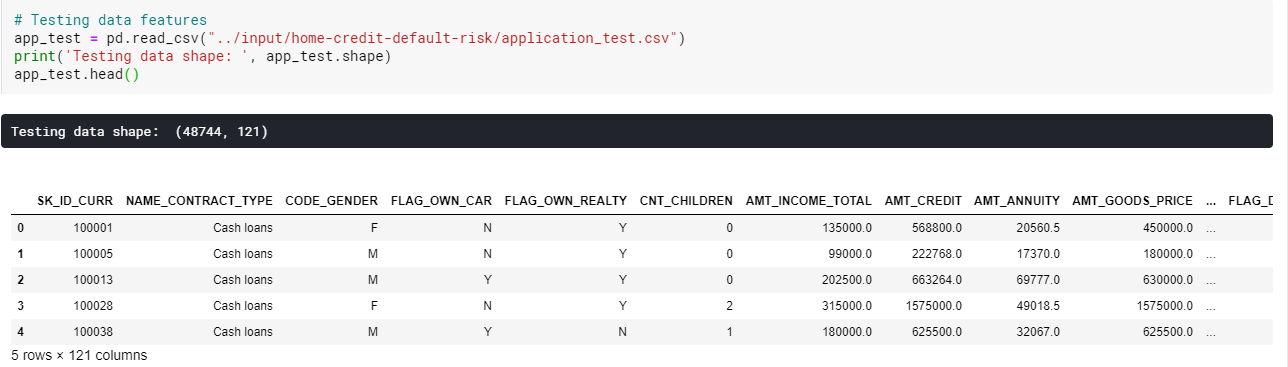
train/test 데이터의 shape은 각각 다음과 같다.
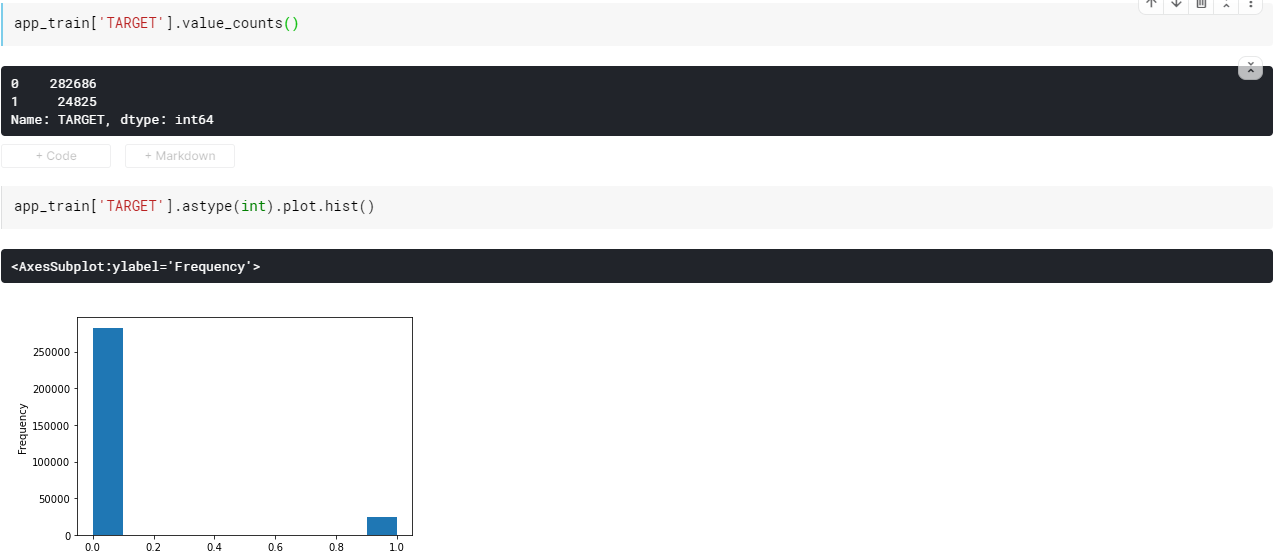
target데이터의 비율을 살펴보니 0클래스가 지나치게 많은 것을 확인할 수 있었습니다.
-여기서 우리는 제때 갚지 못한 대출보다 제때 갚은 대출의 비율이 훨씬 많다는 것을 알고, 이러한 불균형을 반영하기 위해서 데이터의 표현에 따라 클래스의 가중치를 부여할 수 있다는 아이디어를 가질 수 있습니다.
결측값
각 column에 대해서 결측값의 수와 비율을 살펴보기 위해 함수를 작성합니다.


결측값의 비율이 높은 것을 확인할 수 있습니다.
여기서 다른값으로 대체하거나, 높은 비율의 결측값을 제거하는 방법도 있지만 이러한 column의 도움여부는 미리 알 수 없으므로 일단 그대로 둡니다.
categorical

data type과 범주형 변수의 수를 살펴보겠습니다.
그 결과 대부분의 범주형 변수가 상대적으로 적은 수의 고유 항목이 있어 이 범주형 변수를 다룰 방법이 필요해보입니다.
(다루기 위해 label encoding이 필요할 것으로 예상)
label encoding

train 데이터의 column에 object 타입의 데이터 중 2개 이하인 고유 항목을 label encoding합니다.
train 및 test 데이터 정렬
- 두 데이터 모두에 동일한 열이 있어야 합니다. one-hot encoding은 test 데이터에 카테고리가 표시되지 않는 일부 범주형 변수가 있었기 떄문에 train 데이터에 더 많은 열을 생성했습니다. test 데이터에 없는 train 데이터의 열을 제거하려면 데이터프레임 정렬작업이 필요합니다.
EDA anomalies
EDA를 수행할 때 주의해야 할 점은 data anomalies이다. 근데 이 데이터에서 DAYS_BIRTH column을 살펴보면 현재 대출 신청과 비교하여 기록되므로 음수이다. 그래서 연도별 통계를 보기위해 -1을 곱하고 일 수로 나누는 재작업이 필요합니다.
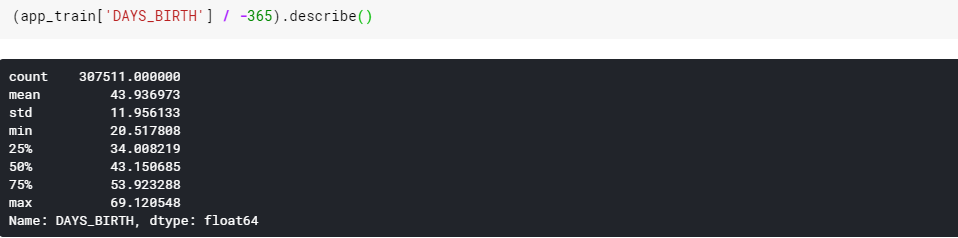
age는 육안으로 보기에 이상한 특징이 없습니다.

하지만 DAYS_EMPLOYED를 살펴보면 maximum value가 1000년이나 된다는 것을 발견할 수 있습니다.

anomalies한 값들을 처리하는 과정을 거치고 통계량을 살펴봅니다.
correlations
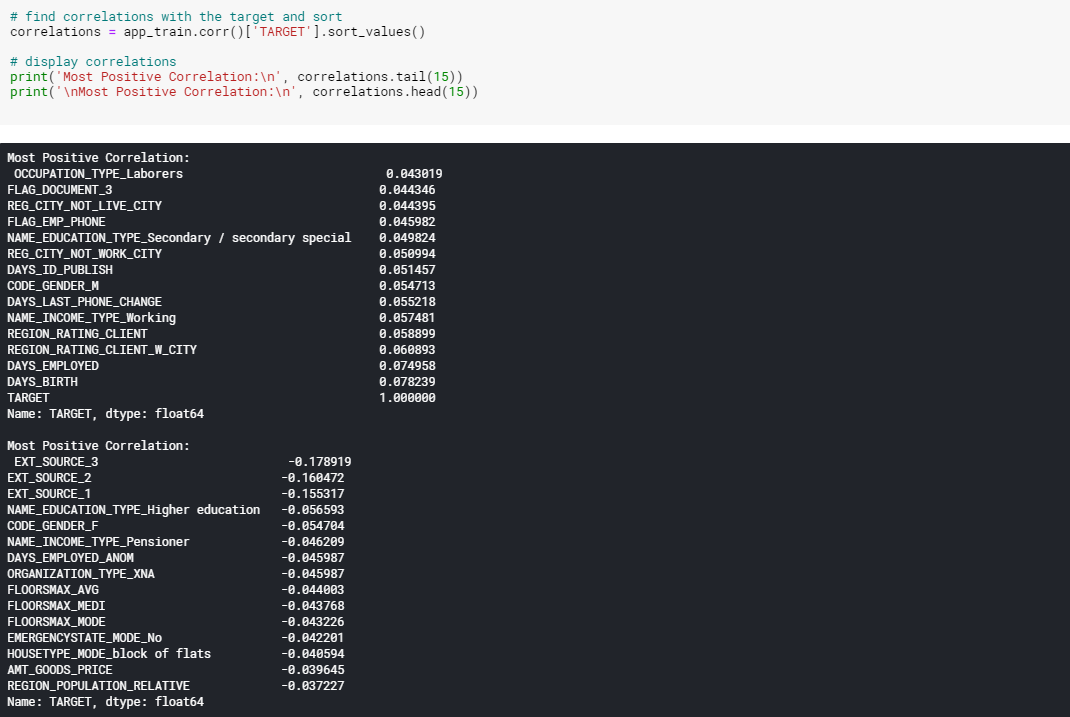
상관관계를 살펴보니 DAYS_BIRTH는 대출 시점의 고객 연령(일)입니다. 상관계수는 양수지만 이 값은 실제로는 음수이므로 나이가 들수록 대출에서 채무불이행(즉, target == 0)이 발생할 가능성이 적다는 것을 의미합니다.
즉 절댓값을 취하면 음수가 될 것입니다.

다시 말해 이 음수가 의미하는 것은 고객이 나이가 들수록 대출금을 제떄 상환하는 경향이 더 많다는 것을 의미합니다.
Kde plot
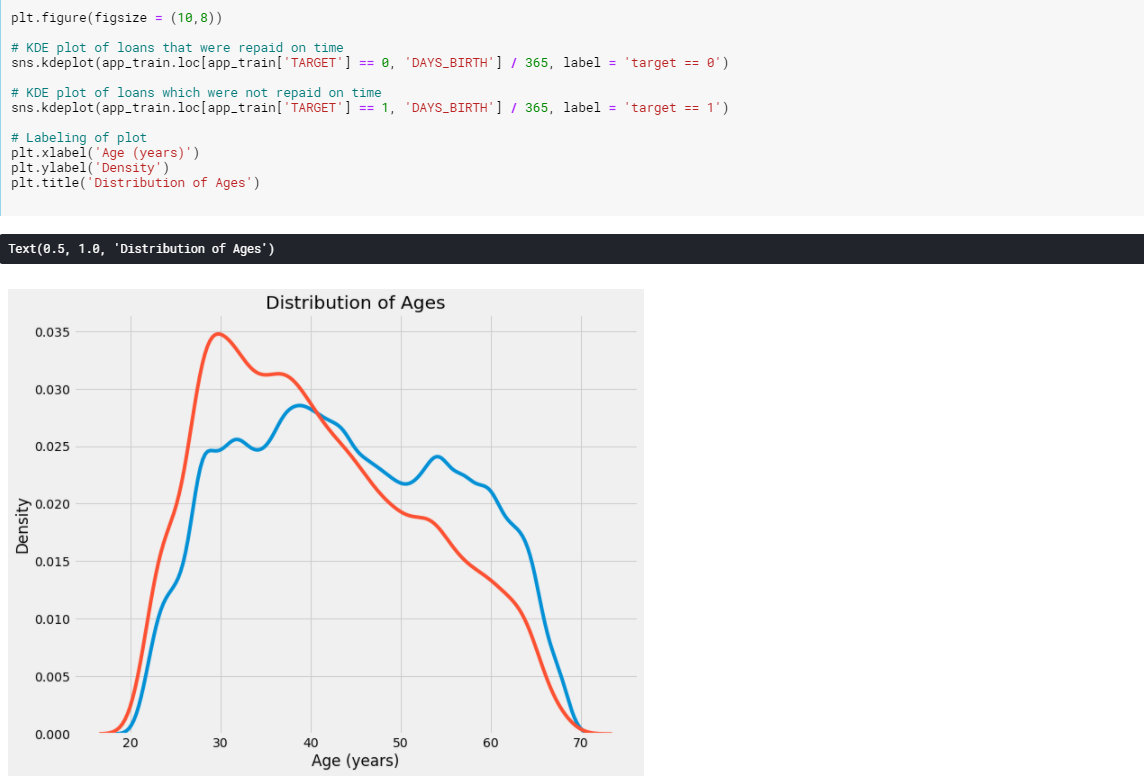
연령에 따른 kde plot을 살펴보니 target == 1의 곡선은 어린 쪽 끝을 향해 기울어진다. 상관 계수가 0.07로 유의하다고 볼 수는 없지만 변수에 영향을 끼치므로 유요하게 사용할 수 있을 것 같습니다.
또 다른 방법으로 평균 연령대별로 대출 상환 실패를 살펴 보겠습니다.
연령 범주를 5년씩 자르고, 각각의 평균값을 계산하여 각 연령 범주에서 상환되지 않은 대출의 비율을 알려줍니다.
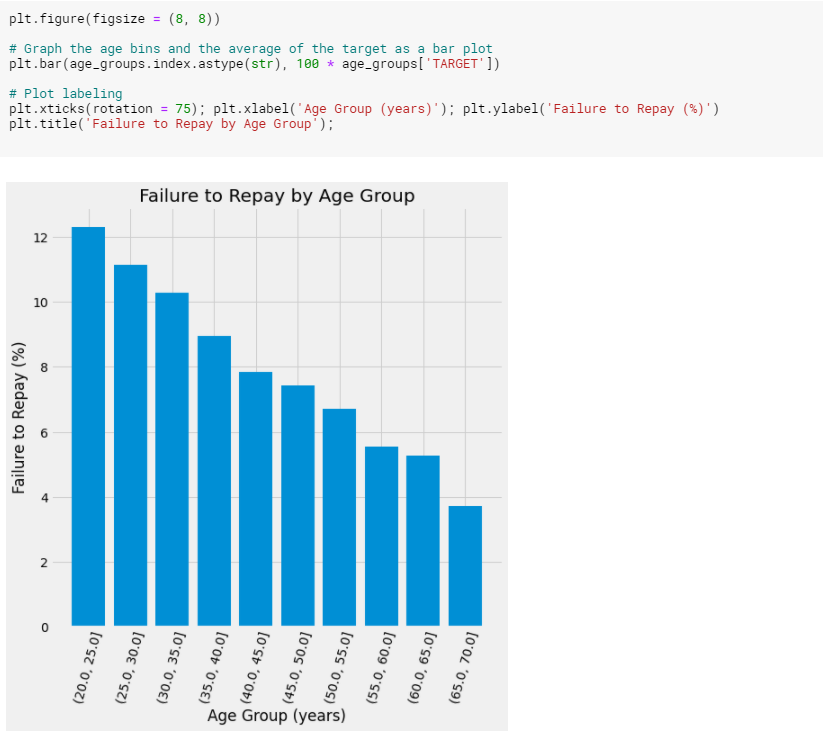
위의 그래프로 보아 분명한 추세가 있다는 것을 확인할 수 있었습니다.
- 젊은 사람들은 대출금을 상환하지 않을 가능성이 더 높고, 최고령 연령대는 상환 불능이 5%미만입니다.
- 여기서 우리는 젊은 고객들이 대출금 상환 가능성이 낮기 때문에, 더 많은 안내나 계획들을 제공해야 하는 등의 아이디어를 얻을 수 있습니다.
다음은 3가지의 강한 음의 상관관계를 가진 target변수를 살펴 보겠습니다.

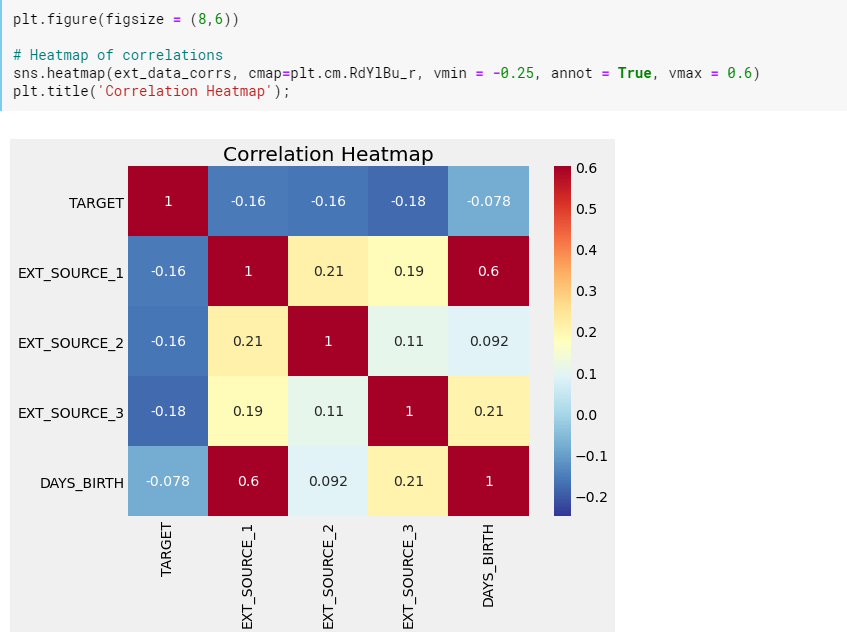
1. 세가지 EXT_SOURCE 모두 target과 음의 상관관계를 가지고 있어, EXT_SOURCE가 증가할수록 대출금을 상환할 가능성이 높다는 것을 알 수 있습니다.
2. 또한 DAYS_BIRTH가 EXT_SOURCE_1과 양의 상관관계로 점수의 요인 중 하나로 연령이 관련있다고 볼 수 있습니다.
각 변수가 대상에 미치는 영향을 시각화한 부분.

EXT_SOURCE_3은 대상 값 간의 가장 큰 차이가 드러난다. 이 특징을 보고 신청자가 대출금을 상환할 가능성과 어느 정도 관계가 있음을 알 수 있습니다.
Pairs Plot


이 plot은 red는 대출금을 상환하지 못하는 blue는 상환하는 것을 나타내고, EXT_SOURCE_1
과 DAYS_BIRTH는 양의 선형관계를 보이는 것을 알 수 있습니다.
Feature Engineering


필사한 커널에서 imputer는 버전이 맞지 않아 simpleimputer를 사용하게 되었습니다. imputer는 누락된 값을 손쉽게 다루도록 해주는 기능을 가집니다. 누락된 값을 특성의 중간값으로 대체한다고 지정 후 imputer 객체를 생성합니다.
각 특성의 중간값을 계산해서 그 결과를 객체의 statistics_속성에 저장합니다.
polynomial features를 통해 유용할만한 새로운 feature들을 생성후 상관관계를 살펴봅니다.
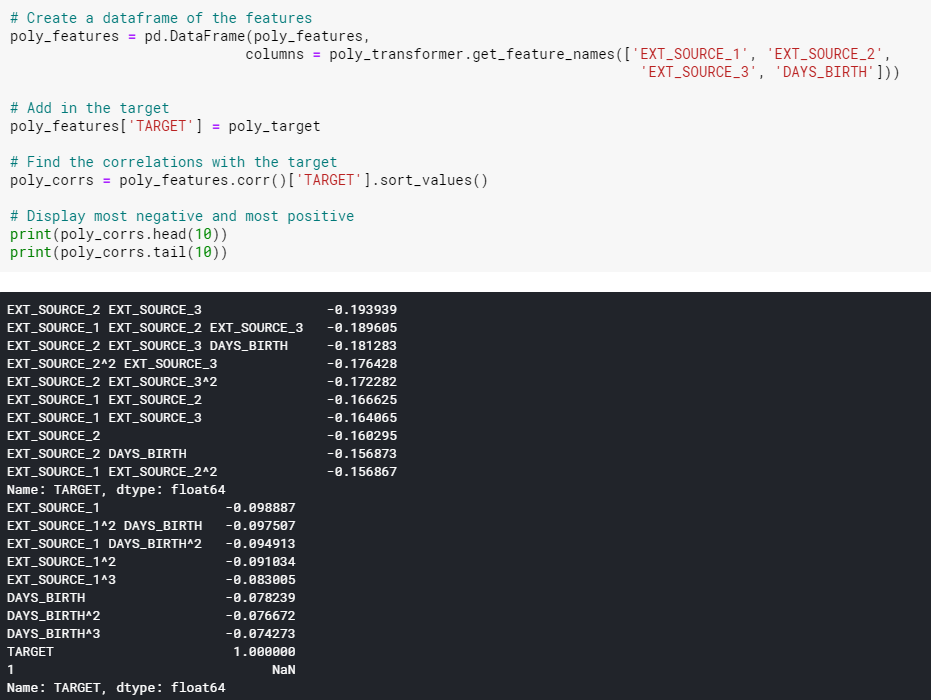
새로운 변수 중 몇개는 원래 특징보다 더 큰 상관관계를 가지고 있습니다.

모델 훈련에 사용할 새로운 변수들을 생성합니다.


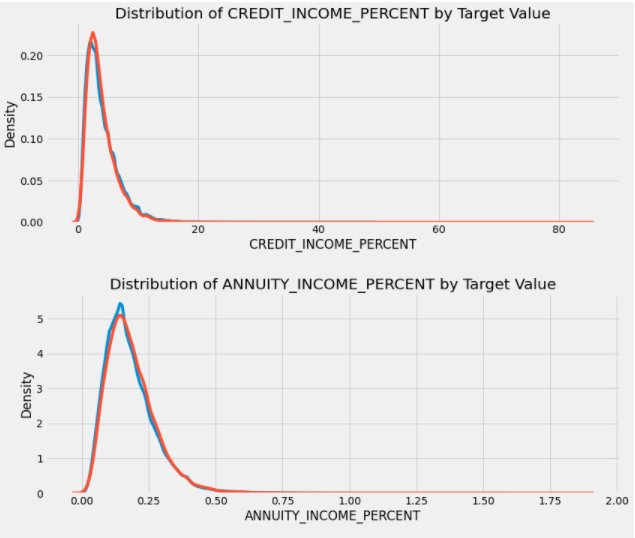
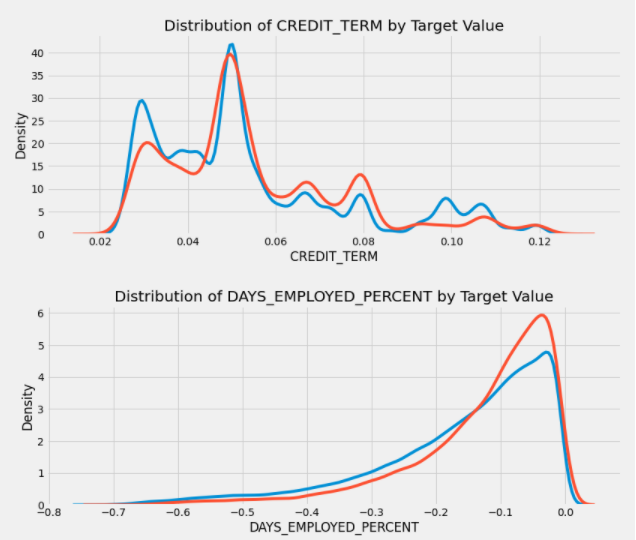

Logistic Regression

대표적으로 Logistic Regression을 통한 결과입니다.
'Kaggle' 카테고리의 다른 글
| [kaggle] 데이터분석 진행해보기(중고차 가격 예측) (1) | 2021.03.08 |
|---|---|
| [kaggle] 필사하기 (Porto Seguro's Safe Driver Prediction) (0) | 2021.01.26 |
| [kaggle] 필사하기 (Santander Product Recommendation) (0) | 2021.01.21 |


